What is Spring Batch?
Spring Batch is a lightweight, broad batch framework that builds upon the characteristics of the Spring Framework that enables the development of robust batch applications, which plays a vital role in the daily operations of enterprise systems.
Spring Batch provides many reusable functions that are necessary for processing records with large volumes, along with tracing and logging, job processing statistics, transaction management, job restart, skip exception, and resource management. The lightweight framework can provide advanced features with technical services that enable extremely high-volume and high-performance batch jobs through smart partitioning techniques and optimization. This tutorial will teach you all about the Spring Batch you need to know using Spring Boot from beginning to advance.
Spring Batch Objectives and Usage
Typical Batch Jobs generally perform the following tasks:
- Reads a large number of data records from a file, database, or queue.
- Processes the read data in some fashion according to the requirement.
- Writes back the processed data in the modified form in the desired location.
In an offline environment, Spring Batch automates the bigger transaction process into smaller chunks of operations. The combination of those smaller chunks will give back the same set of transactions.
In an offline environment, Spring Batch automates the bigger transaction process into smaller chunks of operations.
Besides the normal use case scenarios, Spring Batch supports the business scenarios like the following:
- Commit Scheduled batch jobs periodically.
- Concurrently running multiple batch processes.
- Massive parallel batch processing has millions of records.
- Scheduled or Manual restart after the failure of the process.
- A partial process like skipping records, for example, on rollback.
- The whole-batch transaction, i.e. processing the large scale of data stored in files or stored procedures or scripts.
Spring Batch also has technical objectives, which are being discussed as follows:
- With the Spring Batch framework, the batch developer focuses on concrete business logic and lets the framework take care of the infrastructure.
- Spring Batch provides a clear separation of concerns between the batch execution environment, the batch applications, and their infrastructures.
- In Spring Batch, there are multiple common and core execution services as interfaces are available that any project using it can implement it.
- Spring Batch framework makes it easy to configure, extend and customize the services using the Spring framework in different process layers.
- Spring Batch provides a very simple deployment model, separating the applications from the architecture jars built by using Maven, making it really easy to deploy the application.
Spring Batch Architecture and Components
Any experienced batch architect can comfortably get familiar with the Spring Batch architecture. There are Steps and Jobs and developer-supplied processing units called ItemReader and ItemWriter. The descendant diagram highlights the core concepts that make up the domain language of Spring Batch. A Spring Batch component Job has one too many Steps, each of which has one ItemReader for reading the data from the database or file, an ItemProcessor for modifying the read data from the file or database, and finally, an ItemWriter for writing the processed record to the desired destination. A Job in the Spring Batch is launched with the JobLauncher, and metadata about the currently running process is found to be stored in JobRepository.
Job
Spring Batch follows a traditional batch architecture, with a job repository doing the work of scheduling and interacting with jobs. A job can contain multiple steps. And each step typically follows the sequence of reading, processing, and writing data.
Step
A Step that assigns a Job to carry out its duties. This is a fantastic tool for handling inter-job dependencies as well as for modularizing complex step logic into something that can be tested independently. This step can also be utilized as a worker in a parallel or partitioned execution because the task is executed with parameters that can be derived from the step’s execution.
ItemReader
Data delivery interface using a strategy. Implementations are anticipated to be stateful, will be called several times for each batch, and will return null once all input data has been used up. Each call to read() will return a distinct value. Clients of an ItemReader should be aware that implementations are not required to be thread-safe. We need to handle transactions in an asynchronous batch. Therefore, a richer interface (such as one with a peek or look ahead) is impossible.
ItemProcessor
Interface for changing an item. This interface offers an extension point that enables the application of business logic in an item-oriented processing scenario given an item as input. It should be emphasized that while it is technically possible, it is not required to return a different type from the one that was provided. Returning null also signifies that the processing of the item shouldn’t continue.
ItemWriter:
Standard output operations interface. The class that implements this interface is in charge of serializing items as required. In general, it is up to the implementing class to choose the mapping technology to employ and how it should be set up. The responsibility for flushing any internal buffers falls on the write method. On a subsequent rollback, it is typically also essential to discard the output if a transaction is still in progress. Normally, the resource that the writer is delivering data to should be able to handle this on its own.
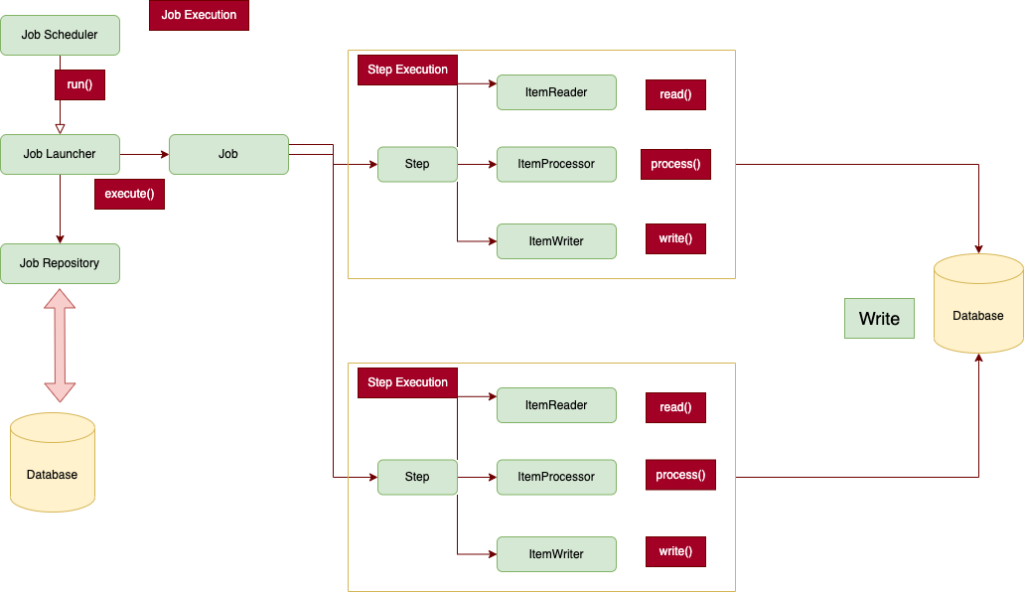
Following are the Spring Batch Components in a well-explained manner.
Spring Batch Setup with Demo Example
The dependency required for injecting the dependency of Spring Batch into the Spring Application is the following which will be going to make the application perform the batch processes.
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-core</artifactId>
<version>4.3.0</version>
</dependency>
Step 1: Spring Batch Jobs: Entity Layer
The first step is to define an Entity layer which will define what data will be retrieved from the database. Create an Employee Class with the following attributes init in the domain package:
@Data
@Entity
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Employee {
@Id
private String id;
@NotEmpty(message = "Name can't be empty")
private String name;
@NotEmpty(message = "Email can't be empty")
private String email;
@NotEmpty(message = "PhoneNumber can't be empty")
private String phone;
@NotEmpty(message = "Designation can't be empty")
private String designation;
@NotEmpty(message = "Email can't be empty")
private String accountNumber;
private String accountHash;
}
Step 2: Repository
Create a repository that will interact with the database layer from the application layer.
@Repository
public interface EmployeeRepository extends JpaRepository<Employee, String> {
}
Step 3: Spring Batch ItemReader Configuration
The following class, ReaderConfig, contains the reader’s configuration in the Spring Batch, which in the processing takes the Data Layer, which has to be read from the Resource file line by line. DefaultLineMapper implements the LineMapper interface, which is used for domain objects to map lines read from a file to domain objects on a per-line basis. The DelimitedLineTokenizer class splits the input data into tokens by using the specified delimiter character, which in most cases is a comma (,). The FlatFileItemReader reads the line one by one according to the Data Entity specified inside of the LineMapper separated by the line delimiter from the resource path provided in the parenthesis.
@Configuration
public class ReaderConfig {
@Bean
@StepScope
protected FlatFileItemReader<Employee> reader(@Value("#{jobParameters['fileName']}") Resource fileName) throws Exception {
DefaultLineMapper<Employee> defaultLineMapper = new DefaultLineMapper<>();
DefaultLineMapper lineMapper = new DefaultLineMapper();
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
tokenizer.setNames(new String[]{"id", "name", "email", "phone", "designation", "accountNumber"});
FlatFileItemReader fileReader = new FlatFileItemReader();
fileReader.setLinesToSkip(1);
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper(fieldSetMapper());
fileReader.setLineMapper(lineMapper);
fileReader.setResource(new PathResource(path));
fileReader.afterPropertiesSet();
return fileReader;
}
}
Step 4: Spring Batch Processor Configuration (Optional)
The Data read by the ItemReader will be passed to the processor, an optional step that takes the read Employee object and can modify after that, it returns a new object of the modified Employee, which is further passed to the Writer for the final step. In the following example, the feign client is being used for calling the other service, which generates the hash of the employee’s account number and returns the modified Employee Object, which is then passed to the writer.
@FeignClient(value = "hash-account-service", url = "http://localhost:8033/", fallback = Fallback.class)
public interface HashClient {
@RequestMapping(method = RequestMethod.GET, value = "/sha256-hash/{accountNumber}", consumes = "application/json")
String generateHash(@PathVariable("accountNumber") String accountNumber);
}
public class EmployeeListProcessor implements ItemProcessor<Employee, Employee> {
@Autowired
private RestTemplate restTemplate;
@Autowired
private HashClient hashClient;
@Autowired
private EmployeeService employeeService;
@Override
public Employee process(Employee employee) {
Employee response = employeeService.findEmployee(employee.getId());
if (response.getAccountHash() == null) {
String hash = hashClient.generateHash(employee.getAccountNumber());
employee.setAccountHash(hash);
}
return employee;
}
}
Step 5: Spring Batch Writer Configuration
The Employee object which ItemWriter receives in the parameter to write it down into the database comes from the ItemProcessor where we can perform any changes to an Employee object we want to. Then we write it down to the database or any file we want to.
public class EmployeeWriter implements ItemWriter<Employee> {
@Autowired
private EmployeeRepository employeeRepository;
@Autowired
private EmployeeService employeeService;
@Override
public void write(List<? extends Employee> list) throws Exception {
PrintWriter writer = new PrintWriter(path );
writer.print("");
writer.close();
if (list.isEmpty()) {
throw new FieldNotFound(404, "Employees are empty", "Empty List cann't be persisted.");
}
employeeRepository.saveAll(list);
}
}
Step 6: Spring Batch Jobs Configuration Layer
The configuration layer of this class creates the Bean at the start of an Application of Spring and runs the job, which contains the steps inside of which the different steps of batch processing start, i.e. read, process, and write.
@Configuration
@Import(ReaderConfig.class)
@EnableBatchProcessing
public class BatchConfig {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
private DataSource dataSource;
@Autowired
private FlatFileItemReader<Employee> flatFileItemReader;
@Bean
public Job readCSVFilesJob() {
return jobBuilderFactory
.get("readCSVFilesJob")
.incrementer(new RunIdIncrementer())
.start(step())
.build();
}
@Bean
public Step step() {
return stepBuilderFactory.get("step")
.<Employee, Employee>chunk(10)
.reader(flatFileItemReader)
.processor(itemProcessor())
.writer(writer())
.build();
}
@Bean
public ItemWriter<Employee> writer() {
return new EmployeeWriter();
}
@Bean
public ItemProcessor<Employee, Employee> itemProcessor() {
return new EmployeeListProcessor();
}
}
An interface for running Jobs. JobLauncher can be used directly by the user but can also be used to easily start batch processing.
Launch CommandLineJobRunner from a Java command. CommandLineJobRunner runs various processes to launch JobLauncher.
public class JobLaunch implements JobLauncher {
@Override
public JobExecution run(Job job, JobParameters jobParameters) {
return null;
}
}
Parameter List and Types in Spring Batch Function
Following is the sequence of parameters each function receives with the number of arguments with their types. The ItemReader receives the single Employee Object, the ItemProcessor takes reads Employee Object and perform required operations, and passes the modified list to the ItemWriter to write it into the database.

Conclusion
In the modern era of Big Data, Spring Batch provides you with the following advantages:
- Read thousands of data lines without binding the user to look after the process.
- Run Schedule Jobs and read data.
- Perform manipulation on the read data according to requirement.
- Write the modified data into the database or file.
- Examples are sending emails scheduled on the events or after desired time, like sending bank statements.
To learn more about Spring and Spring Boot check out Spring Boot tutorials for Beginners page.